Model size vs hardware capabilities
Tip:
Refer to the system requirements section and decide on which method of loading the model you wish to use, if you haven't done so already.
To get started with selecting your first model, open huggingface.co in your browser, and go to Models > Natural Language Processing > Text Generation.
You will see a long list of currently available models. You can select any given model to see a model card, or a brief overview of the model's features, terms of use and recommended template or settings. Keep in mind that not all models are free to be used for commercial purposes.
While browsing through, notice that most model names contain a number followed by the letter B. This denotes the number of billions of parameters contained by the given model. For instance, Llama-2-70b-chat was trained on 70 billion parameters.

You will also notice some models with 8x7B in their names. These are Mixture of Experts (MoE) models. In essence, 8 smaller models working in conjunction.
The larger this number, the "smarter" the model will be. However, larger models, while smart, have a downside: using them requires a powerful computer. The larger the "B" number, the larger the memory requirement.
Quantization
Further complicating this calculation is the matter of quantization, or model "quants". In simple terms, the model can be compressed to more easily fit into your memory. However, it will be slightly less "smart" than an uncompressed model.
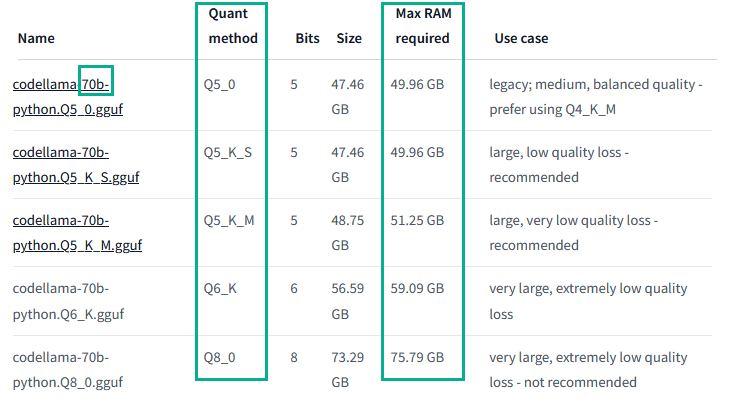
Some model authors provide a table showing exactly how much memory you will need to comfortably run a given model. In this example, a Q8 quant of codellama-70b can fit in 76GB of RAM, but a Q5 quant will fit into 50GB of memory.
Tip:
It's generally agreed that it's better to run a larger model quantized than to run a smaller but unquantized model. It's also agreed that it's best not to go below Q5.
Using this information you should be able to roughly estimate how large a model you can comfortably run on your machine. One approach would be to begin with a small model, a 7B or 13B one, and if it runs well, move up to larger ones.